Welinq's araQne meets NVIDIA CUDA-Q: Distributed Quantum Compiling with GPU accelerated verification

Abstract
Welinq is building the infrastructure layer needed to make distributed quantum computing practical in quantum-augmented data centers. To achieve this, Welinq developed araQne, a distributed quantum compiler for mapping and orchestrating quantum algorithms across heterogeneous resources. By integrating araQne with NVIDIA CUDA-Q, Welinq creates a coherent workflow from distributed quantum algorithm compilation to GPU-accelerated verification of compiled DQC circuits.
Together, Welinq’s araQne and NVIDIA CUDA-Q establish an end-to-end software stack for compiling, verifying, and hence advancing distributed quantum computing toward real-world deployment.
Introduction
Achieving computational quantum advantage for practically relevant industrial applications requires the implementation of large-scale algorithms, tailored for qubit numbers that significantly exceed the capacities of current hardware platforms. As a consequence, scalability continues to be the dominant limiting factor in transitioning quantum computing from experimental systems to practical, large-scale deployment. Additionally, factors such as operational imperfections, noise and decoherence, fundamentally limit the reliable scaling of standalone quantum processors.
Overcoming these limitations will be achieved by a paradigmatic shift: from computation on isolated, monolithic quantum devices to networks of interconnected near-term processors operating collectively as a single computational system. Distributed quantum computing stands out as a critical enabler of scalability, while simultaneously unlocking improved fault tolerance through its natural synergy with quantum error correction.
In this framework, recent proposals [1, 2, 3] on quantum-augmented data centers further illustrate how hybrid architectures, combining classical high-performance computing infrastructure with distributed quantum architectures, can orchestrate large-scale quantum workloads (Fig.1). Such configurations leverage modularity, parallelization across quantum processors and hence mitigating hardware limitations of individual devices, while enabling flexible and scalable quantum computation.

To address this challenge, Welinq developed araQne, a distributed quantum compiler designed to partition and orchestrate quantum algorithms across heterogeneous resources. By integrating araQne with NVIDIA CUDA-Q – the platform for hybrid quantum-classical computing, we are able to connect distributed quantum algorithm compilation with GPU-accelerated verification of the resulting DQC circuits, making araQne compatible with a high-performance quantum software environment and enabling its workflow to benefit directly from NVIDIA GPU simulation resources.
Compiler for Distributed Quantum Computing
Distributed quantum architectures are comprised of multiple quantum processing units (QPUs), interconnected via both classical and quantum communication channels forming a network that effectively operates as a single higher-capacity quantum processor. The interconnection is established via entangled states, distributed over the network. Within this framework, a large-scale circuit representing a monolithic quantum algorithm, is partitioned into a collection of subcircuits, each assigned to a distinct QPU. Operations involving qubits from different QPUs are mediated by entanglement-assisted protocols, in particular gate- and data-teleportation.
At Welinq, we have developed the central enabling component of such architectures: araQne is a quantum compiler for distributed quantum computing, implementing a complete workflow for partitioning large-scale monolithic quantum circuits and distributing them across multiple interconnected QPUs as shown in Fig.2. A detailed presentation of our methods along with the benchmarking result, can be found in our article published in EPJ Quantum Technology [4].
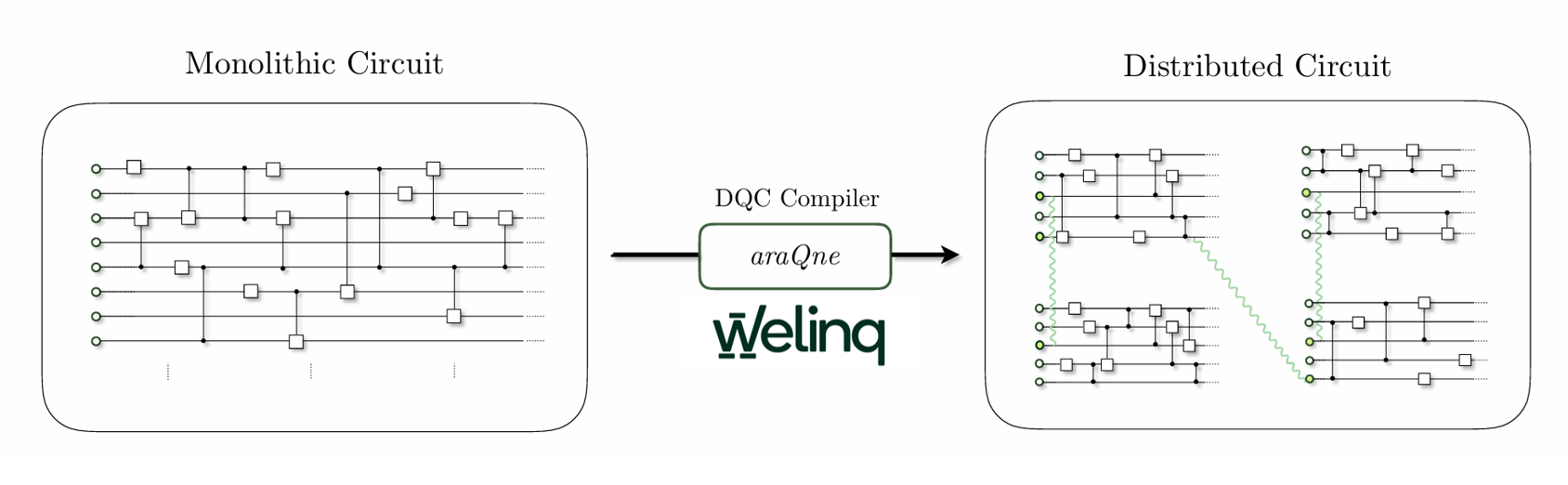
This workflow encompasses qubit allocation and the efficient implementation of non-local gates, while explicitly minimizing the distribution cost, defined as the consumption of entangled resources. Our approach combines circuit partitioning, gate reordering, and a greedy gate-packing heuristic within a hypergraph-based framework, enabling the generation of optimized distributed circuits with reduced inter-QPU communication overhead.
Leveraging our methods, we achieve compilation of quantum circuits with important reduction in the distribution cost, enabling more efficient use of entanglement resources in distributed architectures. One of the most representative results is obtained for the distribution of Random Quantum Circuits (RQCs), constituting a widely used benchmark that captures the diversity and complexity of practical quantum workloads. These circuits are generated by a random combination of single and two-qubit operations, providing a representative testbed to assess how effectively our compiler identifies optimized partitioning for distribution over a network of a given number of QPUs.
Our results are shown in Fig.3 and highlight the tangible benefits of our optimization strategies. We compare the distribution according to our greedy algorithm to that of a simplified implementation without gate reordering and gate packing. Across a range of configurations, we observe a significant reduction in the number of entangled pairs required to execute the distributed circuits. This reduction ranges from roughly 10% for a configuration consisting of 8 QPUs to 19% for 4 QPUs and finally to 30% for 2 QPUs, demonstrating that our methods lead to substantial savings in communication resources. These findings reinforce the importance of compiler-level optimizations in rendering distributed quantum computing not only scalable, but also resource-efficient in practice.
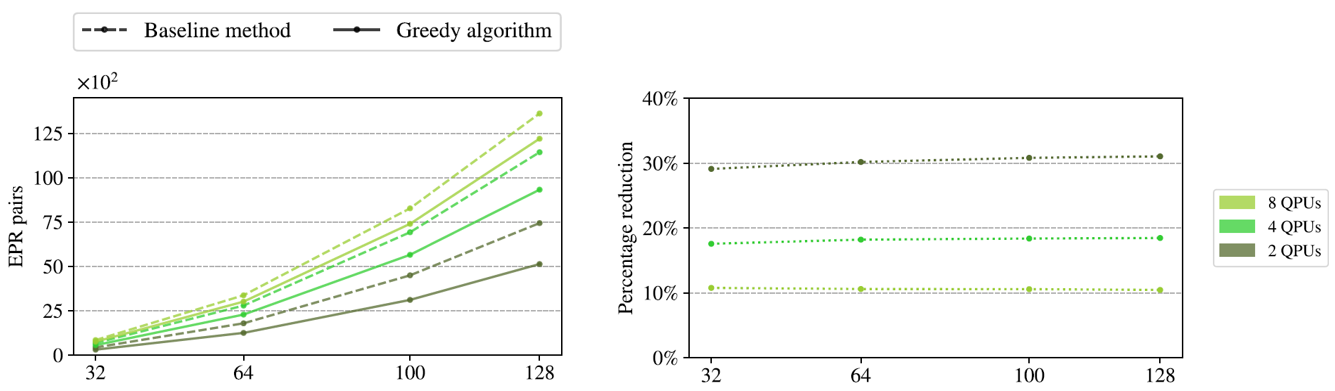
In our work [4], we have additionally benchmarked araQne on the QASMBench 1.4 suite [5], demonstrating the key role of circuit reordering in reducing distribution cost across interconnected QPUs. By isolating such method, we show that gate reordering alone can already achieve significant savings in entanglement resources for distributed quantum computation.
Sliced Statevector Validation for Distributed Quantum Circuit Compilation
Reordering and grouping are essential steps in our distributed quantum circuit compilation workflow. A validation step is therefore useful both as a correctness check and as a debugging tool, helping to determine whether errors have been introduced during the reordering or grouping process.
To this end, we developed a sliced-statevector validation methodology for distributed compilation. To execute this validation efficiently at scale, the workflow leverages the GPU statevector simulator backend available within NVIDIA CUDA-Q [6]
Instead of comparing the full original and reordered circuits, which becomes infeasible for large systems, the circuit is decomposed into fixed-size qubit slices. In our experiments, we use slices of 20 qubits, a size manageable for GPU-based statevector simulation. Each slice is then verified independently by constructing the corresponding projected circuits before and after reordering and comparing their output statevectors, as shown in Fig.4.
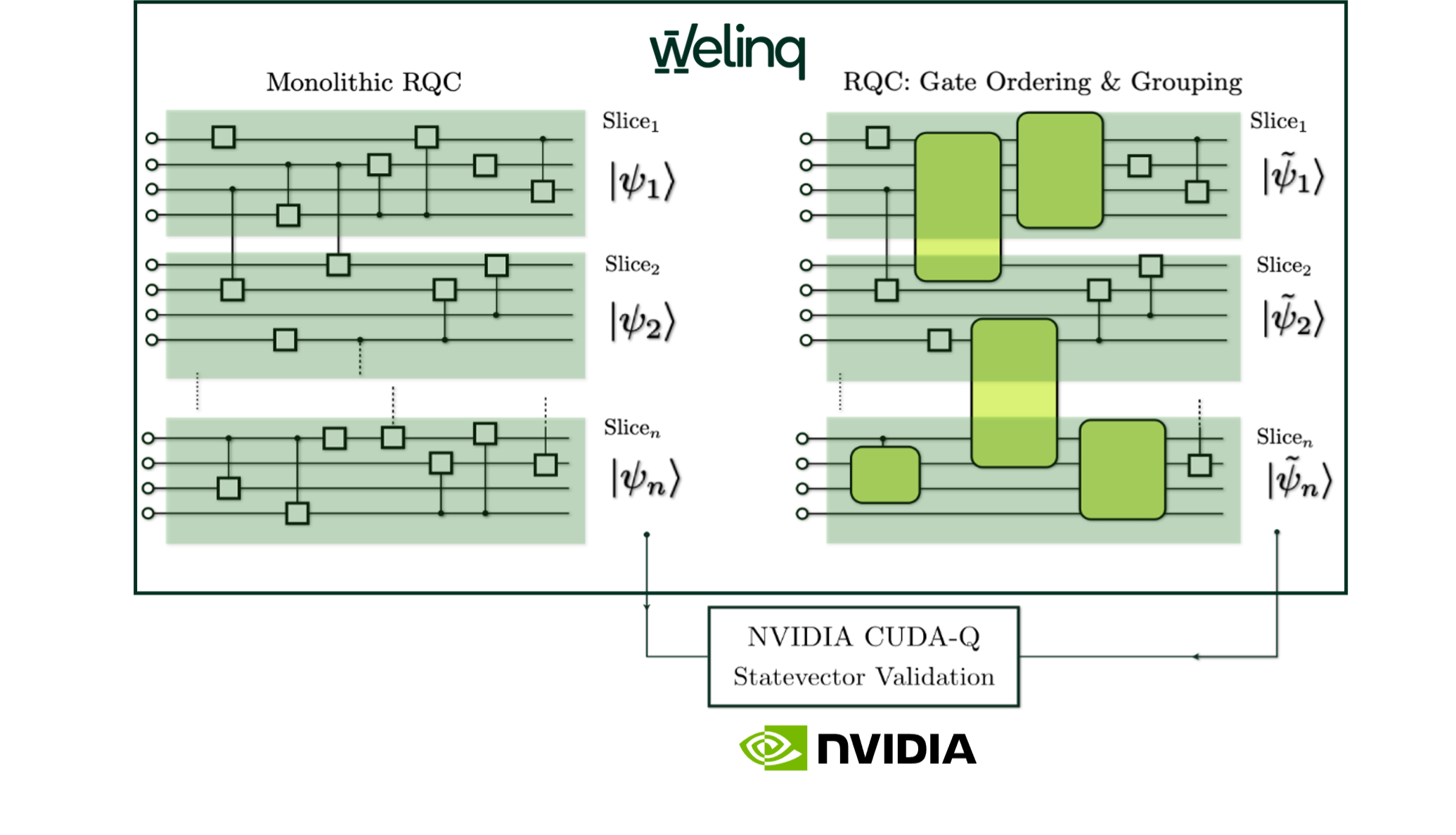
External controls acting on targets inside the slice are treated as boundary-conditioned operations. By evaluating selected boundary assignments, such method can detect common compiler errors, including spurious added gates, missing operations, incorrect targets, and dropped controls.
For benchmarking, we consider random quantum circuits (RQCs) with a density of 2-qubit gates of 35%. RQCs provide a particularly meaningful stress test because they have no strong exploitable structure and therefore represent a less biased benchmark than structured circuits. We hence compared the runtime of the validation procedure on NVIDIA L4 Tensor Core GPU against a CPU-based statevector simulation baseline.

The results of Fig.5 show that GPU-based validation is consistently faster than CPU-based validation, with an improvement of at least one order of magnitude in the tested regimes. In the first experiment, we fix the circuit size to 100 qubits and increase the number of layers up to 100, which also increases the number of two-qubit gates. In the second experiment, we fix the circuit depth to 10 layers and increase the number of qubits up to 1000. In both cases, the GPU backend provides a clear runtime advantage over the CPU baseline.
Conclusions
Leveraging GPU-accelerated statevector simulation with NVIDIA CUDA-Q, we demonstrate efficient validation of distributed quantum circuits, ensuring consistency under common compiling errors while significantly reducing runtime. This highlights the strength of our approach, which combines advanced compilation techniques with high-performance simulation toward making large-scale distributed quantum workflows more tractable and efficient. Keeping verification runtimes low is a necessity for handling the demanding computational loads expected in quantum-augmented data centers. Our results show that combining advanced compilation techniques with accelerated simulation is key to improving the performance and scalability of distributed quantum computing.
By combining araQne's distributed compilation capabilities with accelerated validation through NVIDIA CUDA-Q, Welinq is advancing the software infrastructure required for quantum-augmented data centers and large-scale distributed quantum computing, making it also compatible with the high-performance computing environment needed to validate and scale these workflows in practice.
Bibliography
[1] D. Barral, F. J. Cardama, G. Díaz-Camacho, et al., Review of distributed quantum computing: From single qpu to high performance quantum computing, Computer Science Review 57, 100747 (2025).
[2] M. Caleffi, M. Amoretti, D. Ferrari, et al., Distributed quantum computing: A survey, Computer Networks 254, 110672 (2024).
[3] H. Shapourian, E. Kaur, T. Sewell, et al., Quantum data center infrastructures: A scalable architectural design perspective, arXiv:2501.05598.
[4] Mengoni, R., Nadalin, W., Rennela, M. et al. Efficient gate reordering for Distributed Quantum Compiling in data centers. EPJ Quantum Technol. 13, 65 (2026).
[5] A. Li, S. Stein, S. Krishnamoorthy, et al., Qasmbench: A low-level quantum benchmark suite for nisq evaluation and simulation, ACM Transactions on Quantum Com puting 4 (2023).
[6] https://resources.nvidia.com/en-us-quantum-computing/cuda-q
Related articles

Welinq and OVHCloud Partner on Networked Quantum Computing Architectures

Welinq and Pasqal Accelerate Networked Quantum Computing with Neutral-Atom Technology

Welinq Secures First Sale of its Entangled Photon Pair Source